
今天,我们宣布 Claude 3.7 Sonnet 1 ,这是我们迄今为止最智能的模型,也是市场上首个混合推理模型。Claude 3.7 Sonnet 可以产生近乎即时的响应或延长的逐步思考,用户可以清楚地看到这些过程。API 用户还可以对模型思考的时间进行细致的控制。
在标准和扩展思维模式下,Claude 3.7 Sonnet 的价格与其前身相同:每百万个输入令牌 3 美元,每百万个输出令牌 15 美元——这包括思维令牌。
我们开发的 Claude 3.7 Sonnet 与市场上其他推理模型有着不同的理念。正如人类使用一个大脑进行快速反应和深度思考,我们认为推理应该是前沿模型的一种综合能力,而不是完全独立的模型。这种统一的方法也为用户创造了更无缝的体验。
Claude 3.7 Sonnet 在多个方面体现了这一哲学。首先,Claude 3.7 Sonnet 既是一个普通的 LLM,也是一个推理模型:你可以选择何时让模型正常回答,何时让它在回答之前思考更久。在标准模式下,Claude 3.7 Sonnet 代表了 Claude 3.5 Sonnet 的升级版本。在扩展思维模式下,它在回答之前进行自我反思,这提高了它在数学、物理、遵循指令、编码和许多其他任务上的表现。我们通常发现,在这两种模式下对模型的提示效果相似。
其次,在通过 API 使用 Claude 3.7 Sonnet 时,用户还可以控制思考的预算:您可以告诉 Claude 思考不超过 N 个 token,N 的值可以达到其输出限制的 128K 个 token。这使您可以在回答的速度(和成本)与质量之间进行权衡。
第三,在开发我们的推理模型时,我们在数学和计算机科学竞赛问题上的优化有所减少,而是将重点转向更能反映企业实际使用LLMs的现实任务。
早期测试表明 Claude 在编码能力方面的领导地位:Cursor 指出 Claude 在现实世界的编码任务中再次表现出色,在处理复杂代码库到高级工具使用等多个领域都有显著改善。Cognition 发现 Claude 在规划代码更改和处理全栈更新方面远远优于其他模型。Vercel 强调 Claude 在复杂代理工作流程中的卓越精确性,而 Replit 成功地部署 Claude 从零开始构建复杂的网页应用和仪表板,而其他模型则停滞不前。在 Canva 的评估中,Claude 始终生成生产就绪的代码,设计品味优越,错误大幅减少。
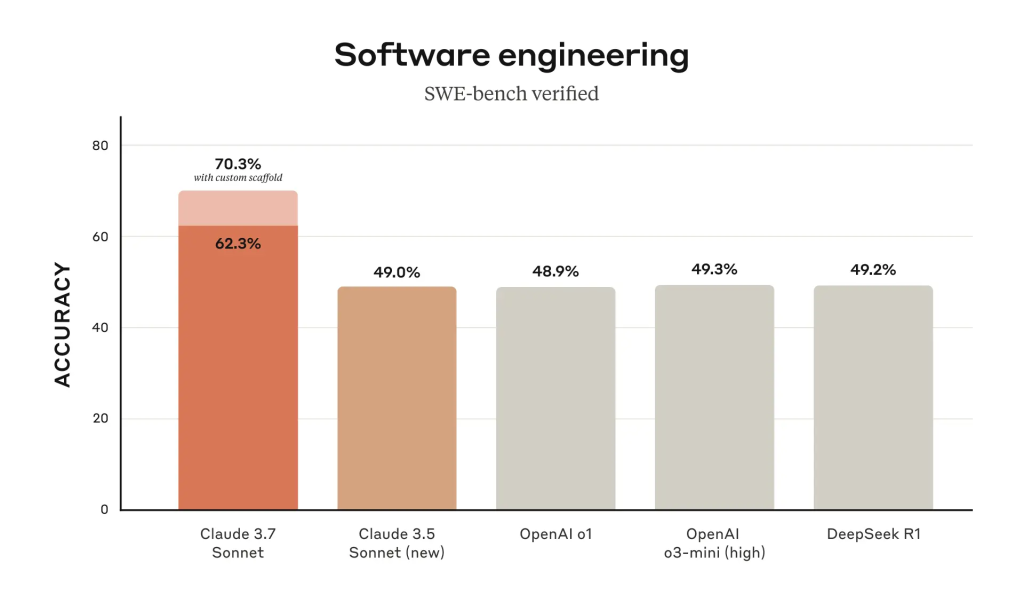
Claude 3.7 Sonnet 在 SWE-bench Verified 上实现了最先进的性能,该基准评估 AI 模型解决现实世界软件问题的能力。
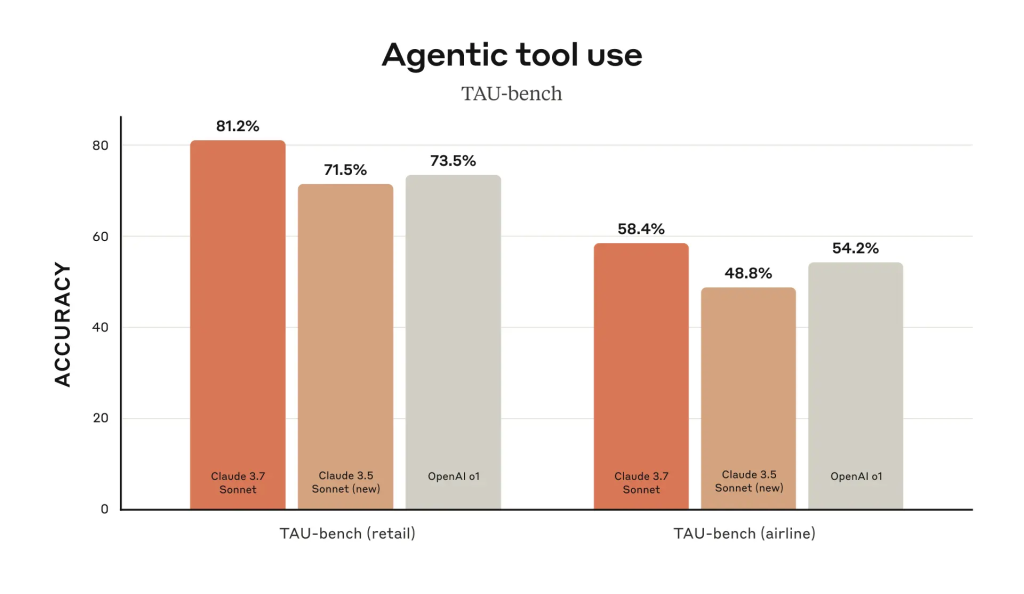
Claude 3.7 Sonnet 在 TAU-bench 上实现了最先进的性能,TAU-bench 是一个测试 AI 代理在复杂现实任务中与用户和工具交互的框架。
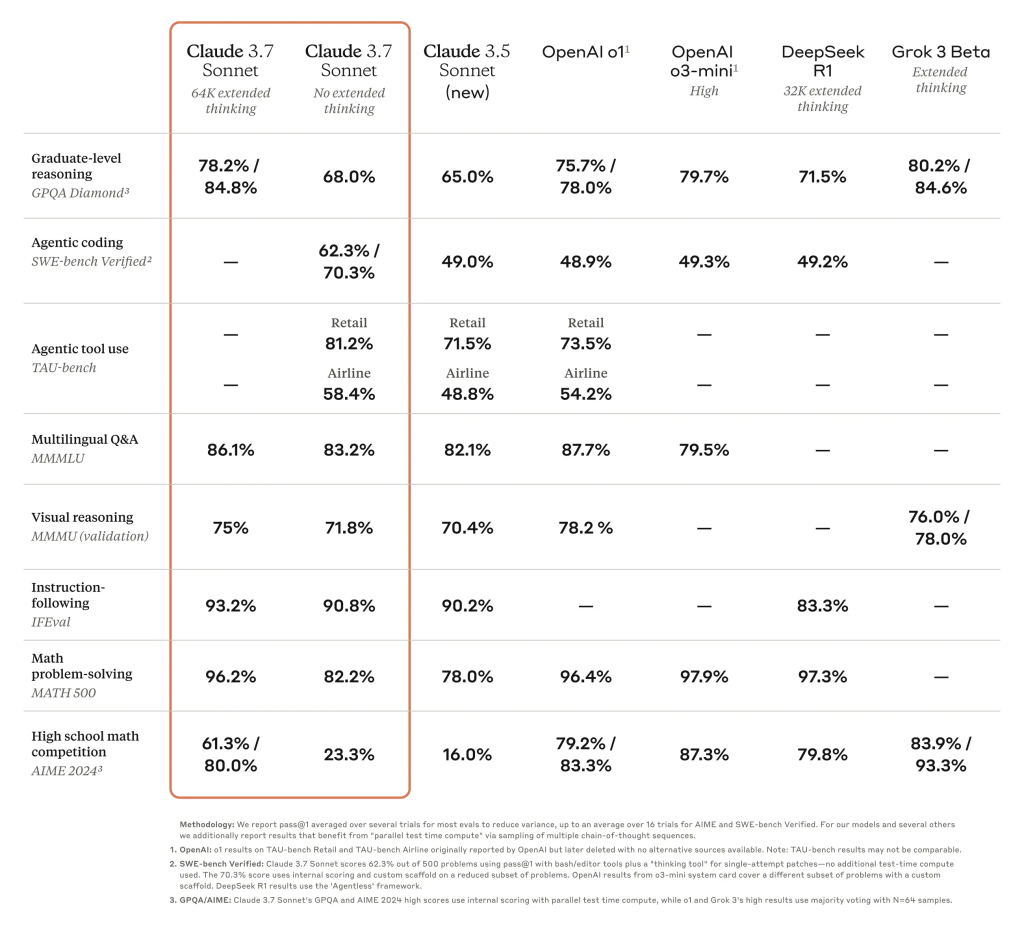
Claude 3.7 Sonnet 在遵循指令、一般推理、多模态能力和自主编码方面表现出色,扩展思维在数学和科学方面提供了显著提升。超越传统基准,它在我们的宝可梦游戏测试中甚至超越了所有之前的模型。
现在,您可以在聚合AI上调用该模型了。
同时,我们还推出了几个延伸模型:
claude-3-7-sonnet-20250219-rev(低价逆向模型,不包含思维链)
claude-3-7-sonnet-20250219-thinking-rev(低价逆向模型,包含思维链)
DeepClaude-3-7-sonnet(DeepSeek-R1满血融合最新3-7-sonnet)
c-3-7-s-20250219(Antropic最新模型,cursor专用模型写法)
